I think optimal insert size depends partly on the experimental design/objectives and sequencing chemistry used (e.g. MiSeq v3 PE 600 would be different than HiSeq PE 200), and partly due to clustering efficiencies. It doesn't _have_ to be 300-400 bp, but that might be the optimal range for the sequencing that you are going to perform.
Let's use this picture to help us:
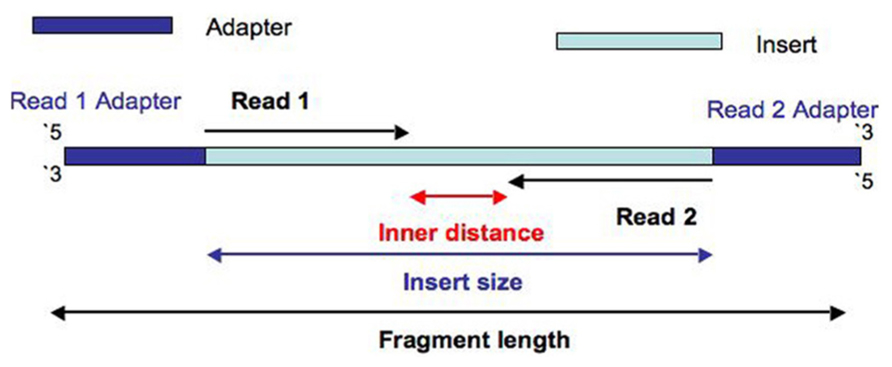
Although it depends on your application, ideally you will have _some_ inner distance, avoiding overlap between Read 1 and Read 2. Let's say you didn't size select your library, and had inserts that ranged from 50 - 500 bp, and that you were sequencing your library on a HiSeq with 2 x 100 reads. After cluster generation, you would have a percentage of clusters that were < 200 bp in length, resulting in overlap of Read 1 and Read 2. Even worse, you'd have some clusters < 100 bp, meaning Read 1 and Read 2 would be identical and have some adapter read-through, "wasting" a certain amount of your sequencing power.
To compound the problem, smaller inserts tend to cluster more efficiently. From the Illumina Tech Note Nextera Library Validation and Cluster Density Optimization:
It is important to consider library size when preparing samples for
cluster generation. Because the clustering process preferentially
amplifies shorter libraries in a mixture of fragments, large libraries
tend to cluster less efficiently than small libraries.
So if you have a range of insert sizes, you expect the smaller inserts to "out-compete" the larger ones during cluster generation, making the above described issues more frequent. Instead, if you size-select your library to a certain range (say, 300-400 bp), you can ensure that your clusters will almost all have the same insert size, and that you will avoid overlap between Read 1 and Read 2 (if you use the right chemistry).
Why not select larger fragment sizes? As noted above, clustering efficiency decreases, and also larger fragments generate larger clusters, thus reducing the maximum cluster density of the flow cell.


Thank you very much,RUSS! You've helped me a lot~