To cluster matirxmy, for this to see which colnames can divided into groups.
d <- dist(matirxmy, method ="euclidean")#dim(matixmy) 232, 121
hc <- hclust(d)
Also, it can be plot like the first figure My question is for tree like figure shows, the accurate names from Left to Right (or R to L) can be showed on figure, but how can I get these names or this new sorted matrix based my cluster result to operate on server?
if I use
g <- cutree(hc, k=6)#4,5
Here can get 6 submatrix based on result of clusters. For me, I just know to extract submatrix by data[which(g==1), ]...data[which(g==6), ]. I tried let k=232,but not the expected result.
Yes, I know the feeling. A useful tip for these things: You can see the structure of a R object with the str command. So, if you run str(hc), you can see all information stored in the hc object, one of which is the order from left-to-right of the dendrogram.

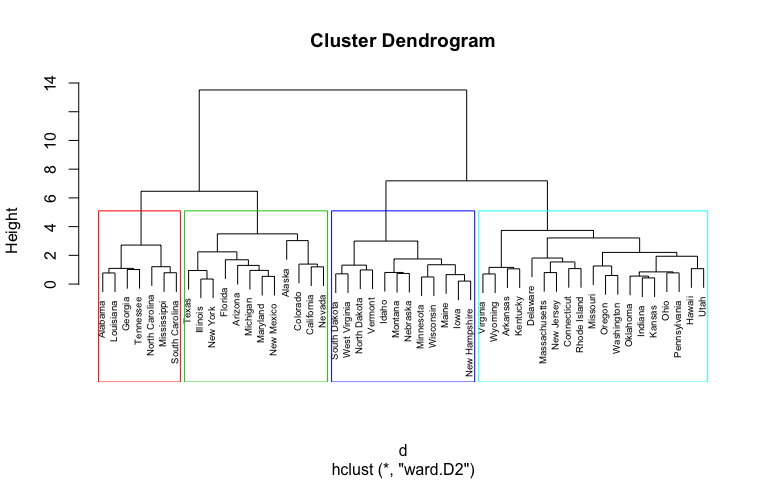


See: How to add images to a Biostars post - you'll need the image URL, not the google referrer URL with the search result page.
Here, the image URL is https://uc-r.github.io/public/images/analytics/clustering/hierarchical/unnamed-chunk-13-1.png
And you'll use the image option on the toolbar, not the external link option. Once done, it should look like this:
I've deliberately made the above image small so it is not usable. You can follow my lead (and my how-to post above) and make it any size you want to.
I see, very clear! Thanks!