Entering edit mode

6.3 years ago
afli
▴
190
Hi everyone, I have a question about binomial test. Suppose there are thousands of coins, some of them are not homogeneous, I flip each coin with various trials, so each coin recieves the number of heads and tails. Then I do binom.test in r to see if I can find the specific coins. (I made this example which is similar with my reseach project, this is simple)
I get the following result:
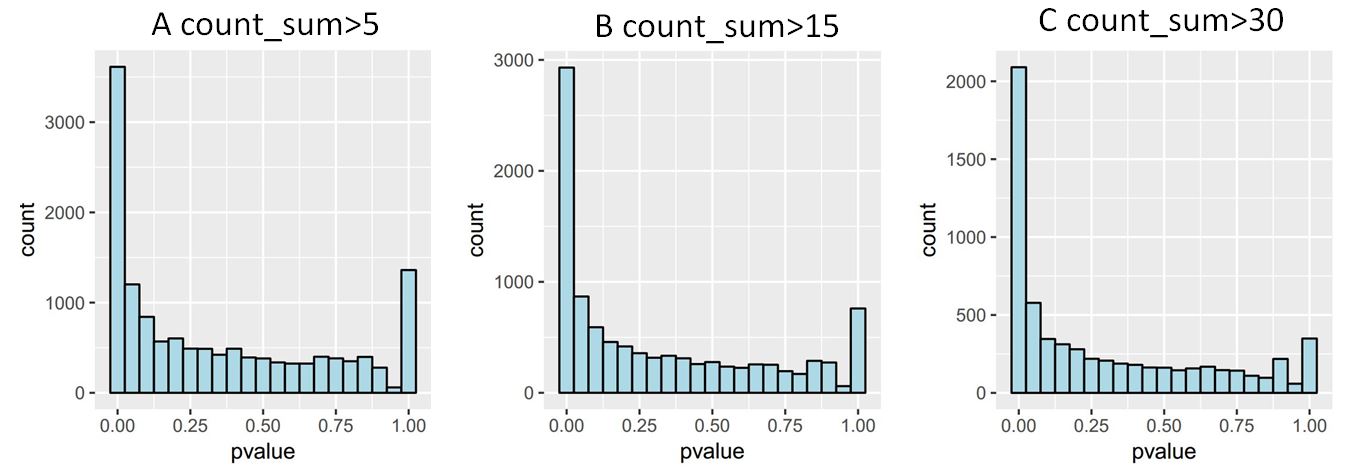
If I filter the counts with more than 5, I get a pvalue distribution of U shape, but if I do more rigorous filtering, the proportion near 1 is decreased. I use the two side method in binom.test. I have two questions.
Why does this U shape occur? Could I proceed my analyse just use count_sum>30?
Thank you! Aifu.

I've seen the related explanation in http://varianceexplained.org/statistics/interpreting-pvalue-histogram/ but I'm still confused with this.