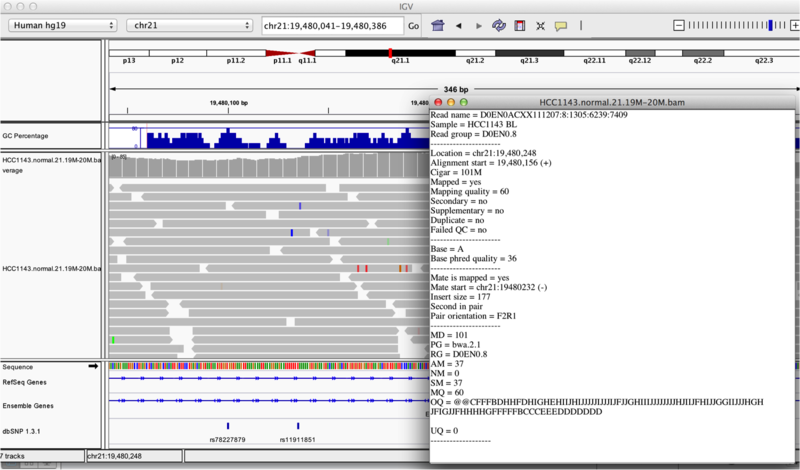
I have a question regarding IGV. When we select a read in particular and look at a SNP, we can view different metrics such as read name, sample, read group etc (https://bioinformatics-ca.github.io/images/Igv_click_read.png ). Could anyone tell me what exactly read name is?
I am asking because I have seen instances of duplicate reads with similar read names as well as different read names and I want to know if I can link either situation to PCR duplicates or something else.
What I am even more confused about is why I see duplicate reads in the first place when I have already used Picard's remove duplicate tool to remove such duplicates.
Any help would be much appreciated.
the read names doesn't given you any information about the sequence of the read. There are generated by the sequencing machine. You see that there are blocks delimited by :. These blocks hold this information in the following order:
FlowCell ID
Lane
Tile Number
X coordinate
Y coordinate
If it would be paired end read, you would have an additional last group with 1 or 2to indicate whether this is the first or second read of the pair.
What I am even more confused about is why I see duplicate reads in the first place when I have already used Picard's remove duplicate tool to remove such duplicates.
The default behavior of picard is to mark duplicates and not to remove them. So the reads are still in your alignment file but have now an additional tag that told other programs that these reads are duplicates. At which position you can see them in igv depends on how your sort the view there. There is also a preference to hide these reads.
Hi finswimmer,
Thank you for your reply. When we use Picard's MarkDuplicates tool, it has an option, Remove Duplicates that I set to true. Would this not remove the duplicates?


{kind=link}
How to add images to a Biostars post
Thank you WouterDeCoster, will use this in future posts.