Entering edit mode

5.5 years ago
SeaStar
▴
50
Hello! I'm searching for suggestion about the new best pipeline/s to find TRANSPOSABLE ELEMENTS in a new assembled genome of a no reference species (octopus). I don't want to use repeatmasker. Can anyone help me?

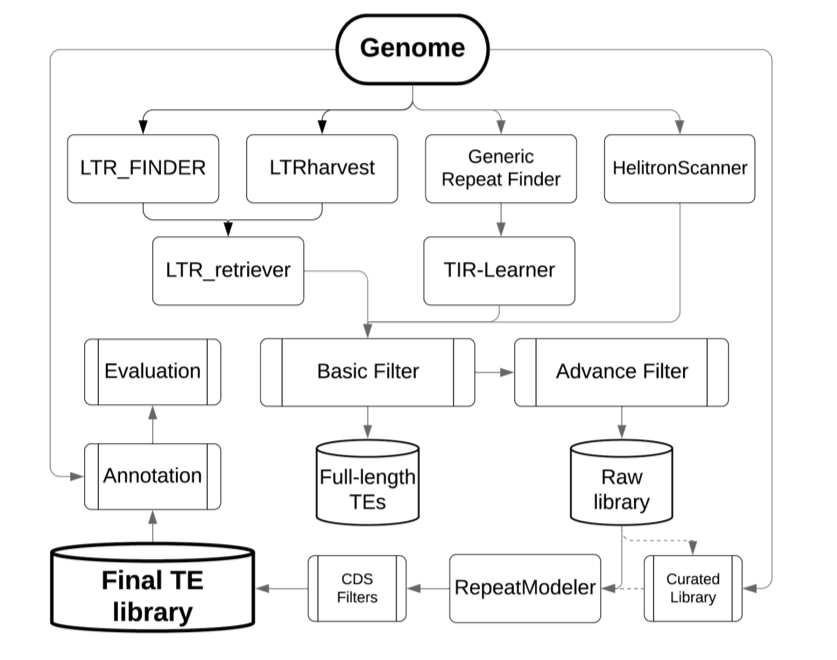


There is nothing wrong with RepeatMasker but it is indeed not a tool to find "new" repeats. You should use if for what's intended for namely masking of a genome using a library of TEs
The pipeline of RepeatModeler + RepeatMasker is the most common approach to identify new repeats genome wide. A recent paper describes RepeatModeler 2 which also has a new classification function for LTR elements. Internally it uses RECON and RepeatScout. Why not give it a try?
indeed, the only caution here is that repeatmodeler is known to be quite aggresive in TE detection and might thus report false positive repeats (typical example: well conserved protein domains might sneak in there as well). So a backscreen of the results of repeatmodeler to a known true protein DBs wil certainly help here.
Good idea, so I am going to blastX my repeat library against NR or SwissProt, never thought about it. I am just wondering about a few things: RepeatMasker/Modeler seems to be a de-facto standard for genome annotations, is that justified? Also, repeat detection still seems to under predict repeat sequence content with some papers claiming that repeat content may be 70% in the human genome.
goh, yes that is justified I think (though there are also alternatives around) as long as you are well aware of what you are doing and what the tool does (/doesn't). And being a bit more cautious will never hurt.
indeed. TE identification is not a straightforward field I feel, also biology does not help as often those TEs are so degenerated that similarity approaches do not pick them up anymore. Much more for improvement here thus.