Hi,
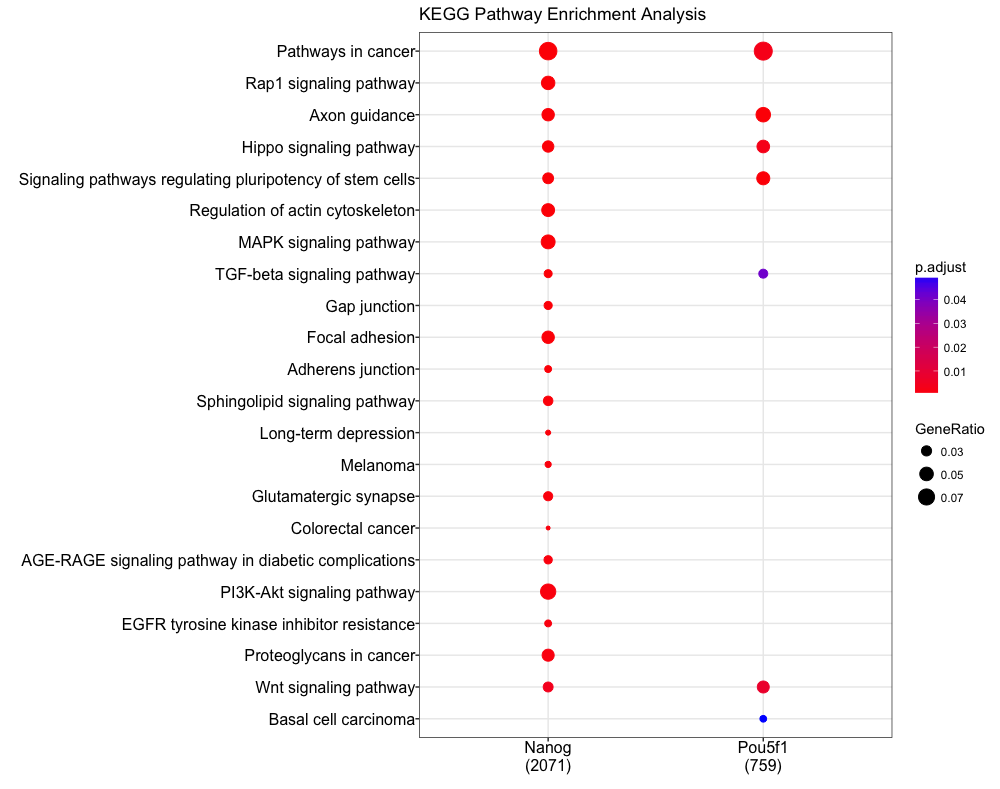
If you have all the data with all the information that you need to make the plot, you can easily do it in R, with ggplot2.
library("ggplot2")
set.seed(1024)
go <- paste0("GO", sample(1000:2000, 5))
data <- data.frame("GOs" = rep(go, 2),
"Condition" = rep(c("A", "B"), each = 5),
"GeneRatio" = 1 / sample(10, 10),
"p.adjust" = 0.05 / sample(10, 10))
ggplot(data = data, aes(x = Condition, y = GOs,
color = `p.adjust`, size = GeneRatio)) +
geom_point() +
scale_color_gradient(low = "red", high = "blue") +
theme_bw() +
ylab("") +
xlab("") +
ggtitle("GO enrichment analysis")
In this case this fake data looks like:
GOs Condition GeneRatio p.adjust
1 GO1980 A 0.1250000 0.050000000
2 GO1213 A 0.1428571 0.025000000
3 GO1308 A 0.1000000 0.010000000
4 GO1396 A 0.2500000 0.006250000
5 GO1351 A 1.0000000 0.008333333
6 GO1980 B 0.3333333 0.007142857
7 GO1213 B 0.1111111 0.005000000
8 GO1308 B 0.1666667 0.016666667
9 GO1396 B 0.2000000 0.005555556
10 GO1351 B 0.5000000 0.012500000
And the plot like this:

The p.adjust usually is transformed into -log10(p.adjust) because it provides a better discrimination scale.
I can help a bit more if you provide the structure of your data.
I hope this helps,
António



{kind=link}
{kind=link}
Clusterprofiler does that