Entering edit mode

4.9 years ago
Rob
▴
180
Hi friends I plotted this box-wisker for TCGA HTSeq data in R. I want to have harf of them as red and half as blue (control vs treatment groups). or is there any better way for boxplot? How can I do that? I just used simple code:
data <- read.table("mydata.csv", header=TRUE, row.names = 1)
library(DESeq2)
mat <- as.matrix(data)
log <- rlog(mat)
boxplot(log)
my plot: https://ibb.co/xXsHtC0

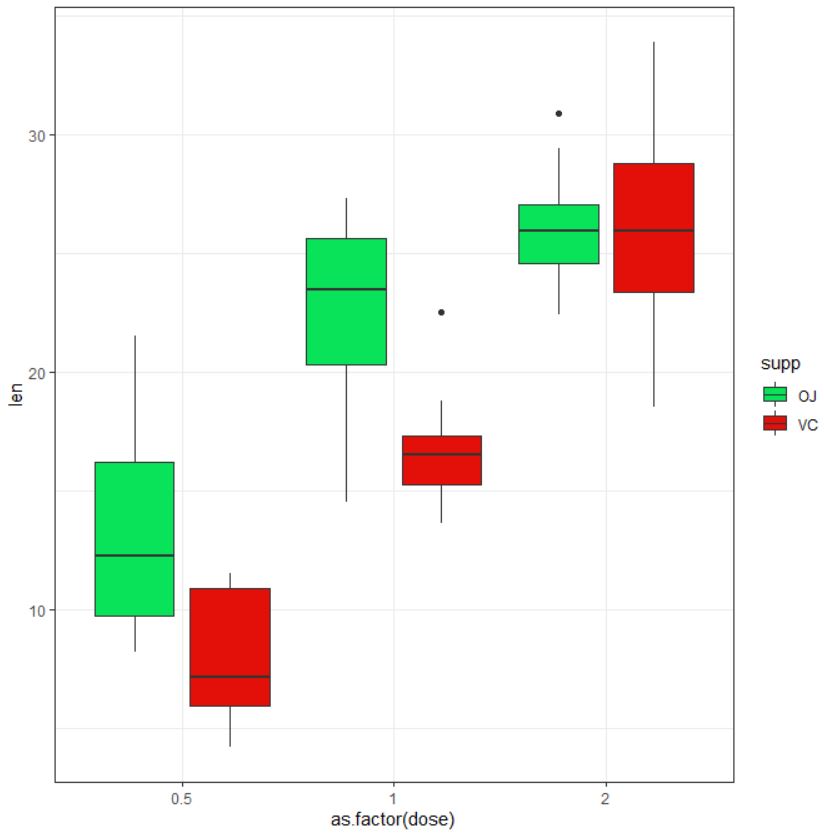
Hi Hamid Thanks this is for one column vs one row data. I do not know how to do it for 64 genes (rows) vs 88 patients (columns). I want patients is x axis and genes in y axis.
Ok then you need to use
meltfunction from thereshapepackage to make a data frame with columns: patient_id, pateint_group, expression_value, gene_name. You may go through this (under section "Top 25 dysregulated gene") to see an example of how to create such dataframe out of a matrix with normalized gene count. Once created the dataframe, use this to make a paired(dogged) box plot. You can download the dataset I used for this example from here.Also you may want to try this:
to make this plot: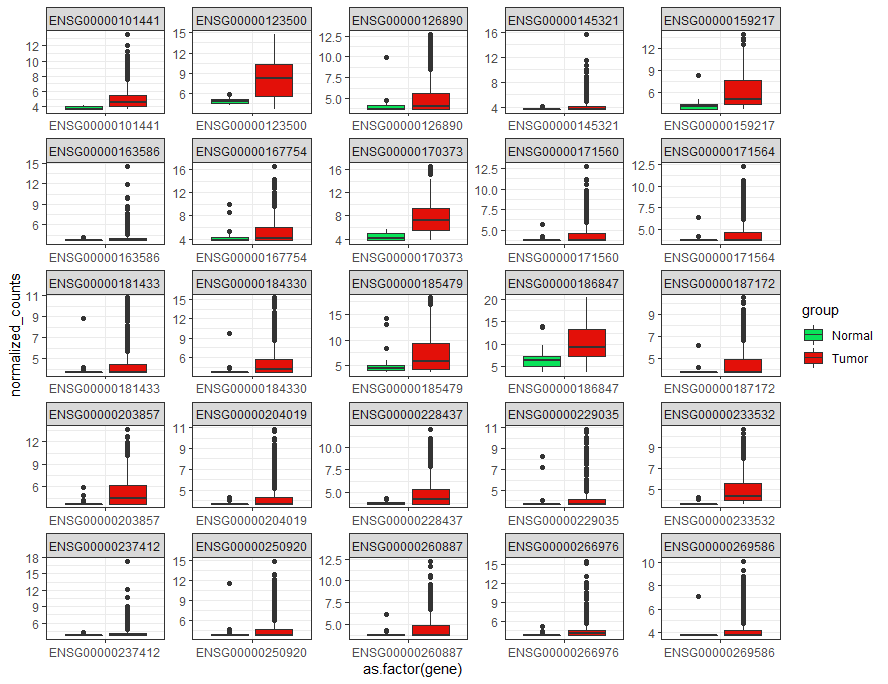
Thank you Hamid. these are really informative. I dobnot see any RNA seq expression values in this dataset you used. it is just patient names and gene list. Is there any way to plot this for significant gene expression? I want to compare expression level in patients. I want each plot to have expression data for one patient.
The third column has "normalized_counts" which is coming from the RNA-seq experiment. Since they are not log-2 or z-score transformed data, the variation in expression plots is very significant. If you want to do a similar task, do the transformation, and then go for plotting. These data are from the top 25 DE genes list.
I am not sure about what you are going to do, but plotting data from a patient (only one ) for a gene (only one gene) won't be informative. Also plotting data from a patient for different genes in a plot! again won't be interesting.
Sorry I dont understand how the input data here is look like. I am not sure if my data format is appropriate for the code. patients in columns vs genes in rows( I know I should normalize and log2 transform). the problem is the appearance of my data and how can I have all the patients in x axis and genes in y axis. Also, how can I seperate these patiebts in two groups (treatment and control ) and show them with red and blue. my data looks like this:
Assumed your data is a data frame namely
dat, this code should work to melt your data:You can find inofrmation about your patient from where you downloaded this data. The TCGA is well-documneted and it would be easy for you to find clinical data.
Thanks
I dont know why I get error:
Because you have not a column with "Gene" name. Indeed I used this label because in the table you provided, the first column is "Gene". Anyway, change this label to the column name of the gene column name. This should work. Also as a tip:
Clearly stated that you have no "Gene" column. Reading errors will save lots of time
Thanks Hamid
I've tried plotting this and it works very well. However I have a question: If you had 200 genes that you would like to compare between the two groups (which is too much to visualise on a plot), how can you get the values that tells you if one group has a significantly differing median than the other group? When you have fewer genes, you can just manually look at if the notches don't overlap between the two groups. And also how to find which of the group that has the higher expression value compared to the other group when not looking at the plot? I'm new in R, sorry if this is a basic question.
Please post this as a separate question, I'm sure people will be happy to help, but hijacking this post is not the way to go about this.