Entering edit mode

11.5 years ago
Honey
▴
200
What is best online tool for calculating power analysis (stat) of RNAseq experiment design? I know about Scotty but it based on another closely related data and may not provide actual scenerio.
Thanks

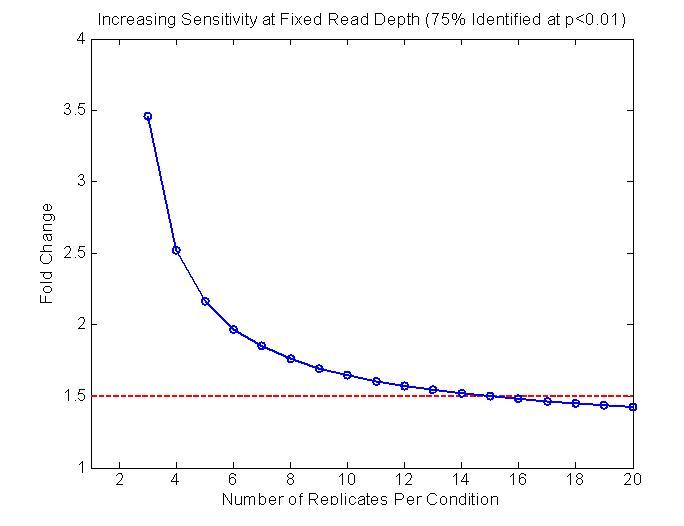

I agree with your observation, I myself has reservation id doing such test but reviewers just keep on hitting this. So I though I would check on that in the forum. Any feedback from other colleagues if I can use tool for GE for RNA-seq?
Thanks